Requirements
- A project containing a choice modeling data set.
- The choice model design in one of the formats listed below.
Method
1. If you wish to run latent class analysis:
- Select Automate > Browse Online Library > Choice Modeling > Latent Class Analysis.
If you wish to run a hierarchical Bayes analysis:
- Select Automate > Browse Online Library > Choice Modeling > Hierarchical Bayes.
A new R output called choice.model will appear in the Report tree on the left, with the following controls in the object inspector form on the left (this one is for latent class analysis):
2. Select one of the following options for Design source. There are five ways to supply the design:
- Experiment question: supply the design through an Experiment Question in the project.
- Experiment design: supply the design through a choice model design R output in the project (created using Automate > Browse Online Library > Choice Modeling > Experimental Design).
- Sawtooth CHO format: supply the design through a Sawtooth CHO file. You’ll need to upload the CHO file to the project as a data set (first rename it to end in .txt instead of .cho so that it can be recognized by Q).
- Sawtooth dual file format: supply the design through a Sawtooth design file (from the Sawtooth dual file format). Likewise, you’ll need to upload this file to the project as a data set.
- JMP format: supply the design through a JMP design file. Again, you’ll need to upload this file to the project as a data set.
For most of these options, you’ll also need to provide attribute levels through a spreadsheet-style data editor. This is optional for the JMP format if the design file already contains attribute level names. The levels are supplied in columns, with the attribute name in the first row and attribute levels in subsequent rows.
3. When Data set, Sawtooth dual file format or JMP format are selected, choose the variables from your design data set containing the Version, Task, and Attributes variables.
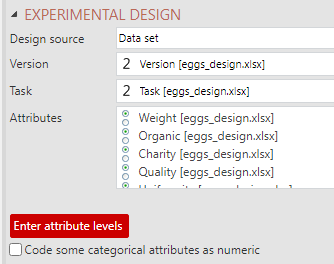
Note, if you are working with an Alchemer (formerly SurveyGizmo) data set, the ResponseID from the conjoint data set is used as Version and Set Number as Task.
4. For most of these options, you'll also need to provide attribute levels through a spreadsheet-style data editor. To enter the attributes, select Enter attribute levels and enter the attribute name and levels in each column: 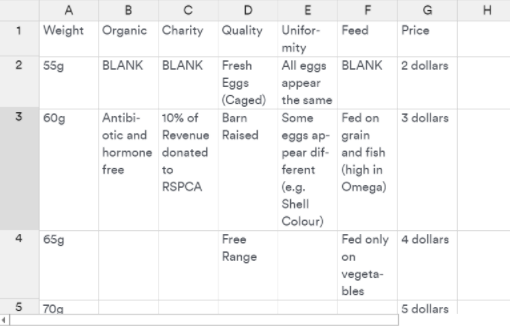
Note that this is optional for the JMP format if the design file already contains attribute level names. The levels are supplied in columns, with the attribute name in the first row and attribute levels in subsequent rows.
5. Next, you'll need to select the Respondent Data. Whether respondent data needs to be explicitly provided depends on how you supplied the design in the previous step. If an Experiment Question or CHO file was provided, there is no need to separately provide the data, as Experiment Questions and CHO files already contain the choices made by the respondents.
For the other methods of supplying the design, the respondent Choices and the Tasks or Version corresponding to these choices need to be provided from variables in the project. Each variable corresponds to a question in the choice experiment and the variables need to be provided in the same order as the questions.
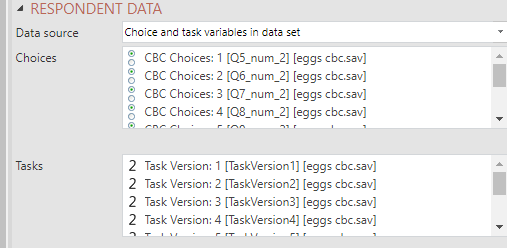
Note the following:
- If you have a 'None of these' option you will need to code this response as 0 or set Missing Values to Exclude from analyses for the relevant variables in your data set.
- If you have a dual-response 'none' design, you will additionally need to select the corresponding 'Yes/No' questions in the Dual-response 'none' choice field.
- Note that if your conjoint data comes from Alchemer, you will need to first add both the conjoint and respondent data files as data sets and go to Automate > Browse Online Library > Choice Modeling > Convert Alchemer (Survey Gizmo) Conjoint Data for Analysis. Q will then add the appropriate questions containing the choices and the design version in the respondent data set.
- All variables in the Alchemer conjoint data file, commonly called "conjoint.csv", must be Number variables to run properly.
- Instead of using respondent data, there is also an option to use simulated data, by changing the Data source setting to Simulated choices from priors. Please see this blog post for more information on using simulated data.
6. Select one of the following options from the Missing data input which determines how Qwill deal with missing data, if any:
- Use partial data is the default setting which removes questions with missing data, but keeps other questions for analysis.
- Exclude cases with missing data removes any respondents with missing data
- Error if missing data shows an error message if any missing data is present.
7. In the Model section, if Latent Class Analysis or Hierarchical Bayes is selected as the model Type, enter the Number of classes you want the model to create.
8. OPTIONAL: Enter a value for Questions left out for cross-validation. If there are too many classes, computation time will be long, and the model may be over-fit the data. To determine the amount of overfitting in the data, set Questions left out for cross-validation to be greater than the default of 0. This will allow you to compare in-sample and out-of-sample prediction accuracies in the output.
9. All other options are more advanced and will be covered in a different article. These can be left at their default values.
10. OPTIONAL: Apply a filter to the model by selecting filter variable from the Filter(s) input at the top of the object inspector.
11. OPTIONAL: Apply a weight to the model by selecting weight variable from the Weight input at the top of the object inspector.
12. Press the Calculate button to generate run the model.
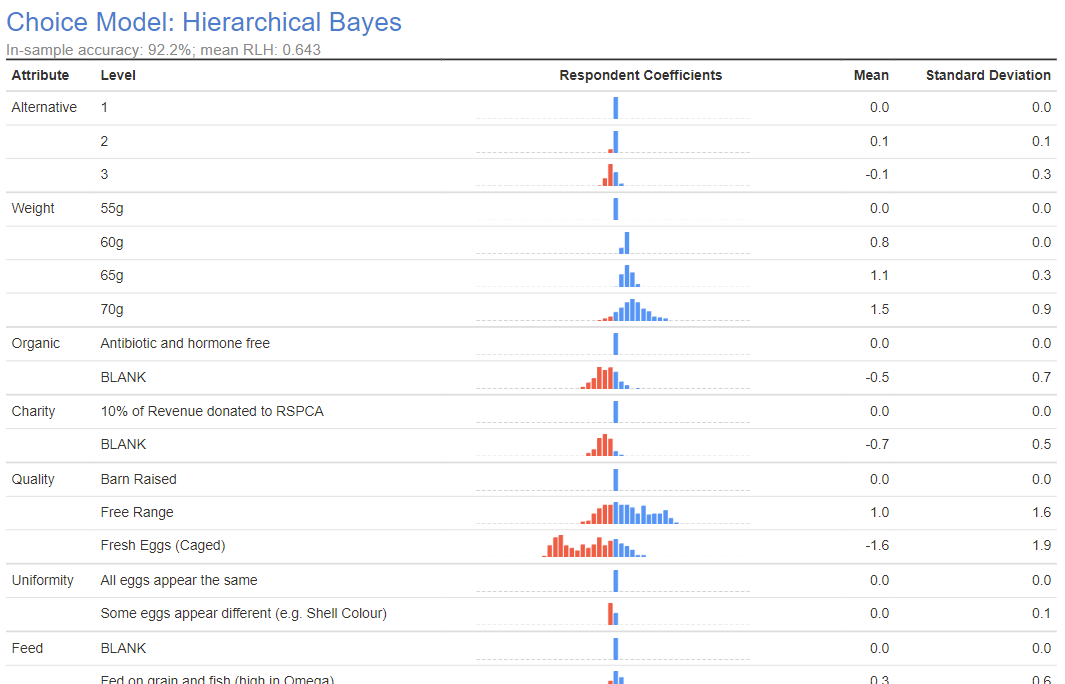
The footer at the bottom of the output contains information about the choice experiment data used and some results from the model such as the log-likelihood and BIC. You can use this for comparison against other model outputs (provided the input data is the same). The in-sample accuracy for when questions are left out for cross-validation can be found in the footer. You should compare this against the out-of-sample accuracy in the subtitle.
Extra features
I have described the process of setting up and running a choice model in Q, but there are still many things that can be done with the choice model output, which are found in the Automate > Browse Online Library > Choice Modeling menu. For example, you can compare and combine outputs into an ensemble model using Compare Models and Ensemble. Diagnostics can be run on the output by highlighting the output and selecting an item from the Automate > Browse Online Library > Choice Modeling > Diagnostics menu, to produce information such as parameter statistics which indicate if there were any issues with parameter estimation. In addition, variables containing respondent coefficients and respondent class memberships can be produced for the output through the Automate > Browse Online Library > Choice Modeling > Save Variable(s) menu.
Note: Using the Efficient algorithm for certain large/complex designs can sometimes be very computationally intensive. In certain situations calculations can take several hours to run. Things will be much faster if you specify prior means and not prior standard deviations for some of the attributes, as this reduces the dimension of the integral that must be approximated each iteration to compute the current D-error.
An alternative to the above would be to run multiple versions of the design, each with 5-10 versions, and editing the random number seed in the R code. You can then combine the outputs together to create a final design.
- Select the design output
- Under Properties > R CODE scroll down to the bottom and edit the code from line 45, to match:
standard.error.respondents = formStandardErrorIndividuals,
seed = 12345)3. Calculate the output as usual.
For each of the different versions of the design output, change the seed= value to any number - as long as it's different from the other versions of the design output. In the above example I've used the rather unimaginative 12345.
Next
How to Save Utilities from a Choice Model
How to Create a Choice Model Utilities Plot
How to Create Correlation Heatmaps from Choice Models Utilities