Introduction
This article describes how to create an entity list from open-ended text data:
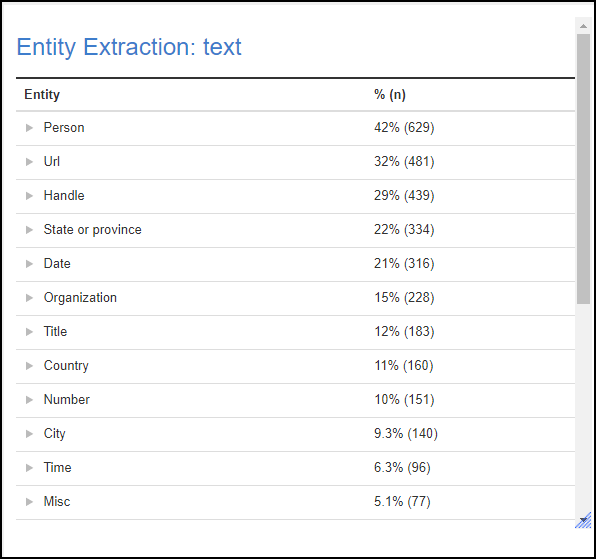
and sentiment scores calculated from an open-end text variable:

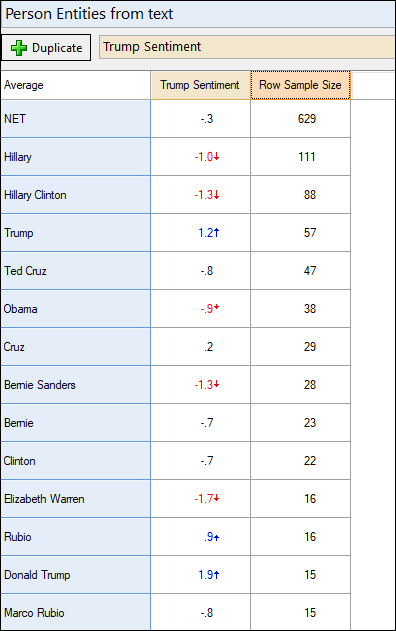
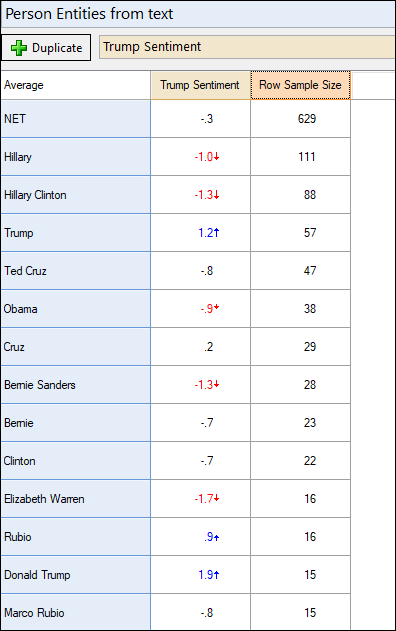
And crosstab them to see sentiment scores by saved categories from an entity list:
Requirements
You will need at least two Text variables in order to perform automatic coding. Text variables are identified with variable type  next in the Variables and Questions tab
next in the Variables and Questions tab
One text variable should be suitable for creating any entity list and another text variable to calculate sentiment.
Method
Extracting the entities
In Q, we extract the entities by clicking
- Create > Text Analysis > Automatic Categorization > Entity Extraction and then selecting the text variable of interest. After a bit of a wait, you get the output below. You can expand out these groups to see what’s been found.
- From Inputs > SAVE VARIABLE(S), click Categories to save the entities as variables in the data file.
Calculate sentiment
- Select the text variable from the output.
- Go to Create > Text Analysis > Sentiment
- A new variable with a Numeric structure will appear in your data set that represents the sentiment score.
Comparing sentiment by entities
OK, so within the Person entity, we’ve worked out who is mentioned in the tweets. What next? We can crosstab this with other information. In the example below, I crosstabed sentiment of the tweets with the Person entity. The averages show the sentiment scores assigned to each tweet that mentioned these names. Scores below 0 indicate negative sentiment. Scores in red indicate statistically significant low sentiment. You can probably work out who sent the tweets!
NEXT
How to Calculate Sentiment Scores for Open-Ended Responses in Q
How to Show Sentiment in Word Clouds using Q
How to Automatically Categorize Unstructured Text Data