Q can analyze any SPSS data file (.sav). However, analysis will be substantially easier and faster if these specifications are used when creating the file.
Languages and Character Encodings
If you load data in Q and see ? characters where there should be text then you have probably loaded an SPSS file from another language that was saved using Code Page mode.
Text in SPSS files can be encoded in two modes:
- In Unicode mode (the default from SPSS version 20 onwards), characters from all languages will load correctly in Q.
- In Code Page mode (the older default), only characters from your computer's default code page can be used. Other characters will appear as ? characters. In Code Page mode your data file can only include characters that are normal in your language, or English. For example, a Japanese SPSS file in Code Page mode can only be used in Q on a Japanese computer.
If you have data that cannot fit into a single encoding then the SPSS file must be made using Unicode mode. e.g. Japanese and Chinese, or English (latin) and Russian (cyrillic).
Fixing an SPSS File from Another Language
You will need to do one of the following:
- Ask your data provider to give you an SPSS file in Unicode mode.
- Run Q on a computer that has been set up to use the same language as is in the data file. If you do this then the project you create on that computer will work on any other computer running Q, regardless of that computer's language (because Q remembers the language of the data file in the Q project file).
- Run SPSS on a computer that has been set up to use the same language as is in the data file. Then switch the file to Unicode mode and resave the SPSS file.
Be aware that if text is wrong in SPSS then it will also be wrong in Q. This can occur when the data has been badly converted between different languages.
Compatible Languages in Code Page Mode
- English is compatible with all code pages, and so can be present in a Code Page mode SPSS file from any country.
- Western European languages share the same "code page" and so can coexist in Code Page mode.
- While sharing many characters, Japanese and Chinese code pages are not compatible.
- There are multiple code pages for Chinese. For example, data from Hong Kong will generally not work with computers in mainland China, and vice-versa.
Data
1. Single Response Questions
Single response questions need to be represented in SPSS as one variable. A data file that uses a different variable for each unique response code of a single response question is not useful. Where there are NETs in a single response question, these should be exported as additional variables. For example, if a question asks about a person's model of car and then this has been used to create NETs of manufacturers, the data should be exported as two variables, one which shows the model of car and another which shows the manufacturer.
2. Multiple Response Questions
Where there are multiple response variables, a binary variable should be created for each possible response. Where a multiple response question contains an Other specify option, the resulting text variable should appear after all of the numeric variables (ie, if the text variable appears in the middle, it will prevent creation of multiple response sets).
Ideally, multiple response questions should be marked as Multiple Response Sets in the SPSS data file. If this is not done, Q will automatically try and guess whether or not variables need to be combined into multiple response questions. This can lead to inaccurate results, requiring additional setup in Q by the user of the data.
When setting up the value labels for multiple response questions, it's important that the same value labels are used for all the options. In particular, the value label should not contain the name of the option being evaluated, as per the below example:
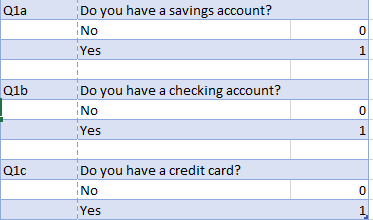
Avoid using the below setup, which is an example of a bad example of setting up multiple response questions:

Common problems with the set up of multiple response questions are:
- Failing to distinguish between missing values versus values that were not selected by respondents.
- Failing to address piping/randomization when creating the data file.
- Using a max-multi format (that is, multiple single response variables, each one recoding a separate response). This is generally only sensible for huge code frames. The reason it's generally not sensible in other situations is that this format does not distinguish between missing data versus options not selected by respondents.
- Confusing the Variable Label with the Value Label and including the category label in the value label rather than in the variable label. Note, most software for generating SPSS data files automatically truncate value labels to 60 characters and variable labels to 120 characters.
- Using inconsistent values preventing Q from automatically recognizing which variables should be set as a multiple response variable set. For example, having the Yes values represented by a 1 for the first option, a 2 for the second option, etc.
3. Grid or looped questions
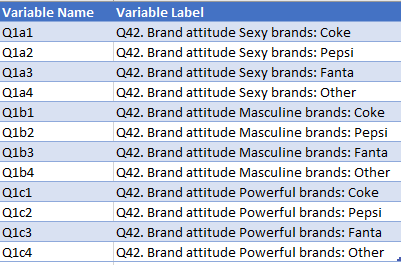
Set up variable labels using identical structures. This will make the use of the file considerably more straightforward. Q will automatically detect the structure in the data and present it as a grid.
For example, the following labels make the interpretation of the grid straightforward:
As a bad example, the following contains inconsistencies Variable labels (eg, last four rows don't include the mention of Q42), preventing Q from auto-detection the underlying structure:
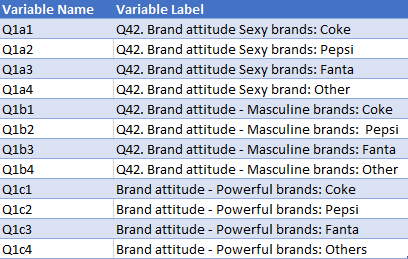
Common problems with the setup of grid questions include:
- Any of the problems with multiple response questions.
- The Label field has been set up with contradictory or inconsistent information, eg typographical errors. While these may seem like minor issues, they prevent data analysis programs from automatically identifying the structure in the data.
In the example above:- An additional space precedes Pepsi for Q1b2.
- Missings with brands in Q1a4.
- An additional s added to Others in Q1c4.
- Q42. is absent from labels for Q1c.
- Truncation of the Label field by the software used to create the data file. For example, the label may read Which of the following brands do you typically consume on a hot day? with the specific brands not listed and thus, there is no way to deduce the correct labeling of the rows and/or columns of the grid (other than assuming they are consistently ordered which can lead to incorrect assumptions and results).
- Repeated labels. For example, if there are two Other/Specify options in the questionnaire they should be given distinct labels like Other 1 and Other 2. Duplicated labels can prevent the automatic detection of grids, as there is no way to differentiate between the two options. Each label in the set must be unique.
- Inconsistencies in terms of the number of alternatives (brands) or attributes in the grid (eg, some brands may not be shown the same attributes as other brands). The solution to this problem is to create new variables with no data.
- The order of the variables is inconsistent. In the example above, the four brands are shown in the same order for each attitude statement, and this is required for successful automatic identification of the grid layout.
Where multiple questions are asked in a loop, it's recommended that all the data appear question-by-question (ie, all the looped variables for the first question, then all the variables for the next, etc.). However, if the intent is to create stacked data, it's instead usually better to structure the data by loop iteration (ie, first show all the data from the first iteration of the loop, then from the second, etc.).
4. Non-Response and other types of missing data
Respondents who were not asked a particular question (ie, were intentionally or unintentionally skipped), should have an SPSS SYSTEM-MISSING VALUEor be flagged as an SPSS USER-DEFINED MISSING VALUE. It's never appropriate to record all missing values in a data file as having a value of 0. This is very important, as for many binary variables the No (Not selected) response is often coded as a 0, making it impossible to determine which respondents said No or didn't select the option, and which were not asked the question.
Where there are multiple different types of missing data (eg, where some questions were not asked of some respondents while others were asked but not answered), these should be coded using different values. Eg, SPSS SYSTEM-MISSING VALUEshould be used where a question was not shown to respondents, and-99 flagged as an SPSS USER-DEFINED MISSING VALUES. Sometimes it's appropriate to treat missing values for some of the questions as being equivalent to a “No” response (eg, giving them a value of 0). For example, if people are asked which brands they have consumed, but are only shown brands that they are aware of, then this would be appropriate. In this instance, it is recommended to include the question twice, once with the SPSS SYSTEM-MISSING VALUEvalues and once with the “No” responses instead.
5. Variable types
- Quantitative variables (eg, estimates of number of flights taken in the last 12 months) should be formatted as Numeric Variables in SPSS, not as String. This will prevent illegal numeric values such as the always popular "-" (dash).
- Date variables, such as interview time, should be stored as date variables in the SPSS data file. If the intent is to change dates when reporting (eg, move the last couple of days of interviewing in a month into the next wave’s reporting), a second date variable should be created which contains this recoded date data.
- Truly numeric variables (eg, estimates of number of flights taken in the last 12 months) should have their Measure set to Scale. Categorical variables should have their Measure set to Nominal., and Ordered categorical variables should be set as Ordinal.
- Ranking questions need to be recorded with a single variable for each item being ranked. Ideally, the most preferred item will have the highest value and the least preferred the lowest value, except where the questionnaire expressly indicates an alternative coding.
- Verbatim responses to open-ended questions and “other specify” options should be stored as String variables when inputting text (eg, other brand used), and as Numeric variables when inputting numbers.
- An ID variable should be included that uniquely identifies each case (typically, each respondent). That is, each case should have a unique value assigned, even if the same person has provided multiple cases of data. If respondents do provide multiple cases then a respondent identifier should be included as an additional variable.
- Any weighting variables constructed by the data collectors should ideally contain a Variable Label that describes the weighting procedure (e.g.,Age-by-gender-by-country 2012). If the weight variable is given the Variable Name of weight in the data file, Q will automatically recognize it as a weight and make it available as a weight.
6. Variable names
Variable names should relate to question numbers. It's often useful if separate question numbering is used for screeners, general questions and classification variables (ie, S1, S, …., Q1, Q2, …, C1, C2,…).
Where a question is represented by multiple variables, it's recommended to use a common prefix (eg, Q4a, Q4b, Q4c), rather than using a different question number (eg, Q231, Q232, Q233).
Where a question is a loop of a multiple response question, this is generally best represented via a common prefix and two separate looping suffixes (eg, Q4a1, Q4a2, Q4b1, Q4b2).
While these are only guidelines, the core principle is to employ a convention that is easily understandable, whereby the variable names are informative as to the structure of the data.
Do not name a variable the same as one of R's common functions. Using one may conflict with some of our automations and cause unintended results. These names include: list, length, exists, assign, names, rep, any, stop, min, max, matrix, attr, sum.
7. Rotations and randomizations between questions
Where different respondents see questions in different orders, this order needs to be removed from the data prior to creating the data file. For example, if respondents have been asked to rate the appeal of a random selection of three of four different products, the data should be exported as if respondents have been asked the same questions in the same order.
Next
How to Convert SPSS Syntax Files into SPSS Data Files
How To Replicate SPSS Custom Tables Significance Tests