Introduction
It can often be difficult and time-consuming to organize raw text data into meaningful insights. Manually coding even a single text question can take several hours, even with relatively small sample sizes. Q has built-in text categorization tools designed to help you quickly categorize your text data to easily find valuable insights. One of these tools is the automatic categorization of text data into a list of items.
Automatic Categorization of Text Data into a List of Items
How to Save the Categories to your Data Set
How to Use Automatic List Categorization to Transform Comma-Separated Pick Any to Categorical
Method
Automatic Categorization of Text Data into a List of Items
Start by first importing your data containing the text variable you want to categorize into Q. With the data loaded, you’re now ready to run the categorization analysis:
- Go to Create > Text Analysis > Automatic Categorization > List of Items.
- In the object inspector (the section that opens on the right of the screen), under Inputs > Text variable(s) select the variable that contains the text you want to analyze.
- Change the Inputs > Minimum category size to the number of categories you would like to classify the data into. For this example, we’ll set the number of categories to 4. This means that Displayr will only show categories that contain at least 2 responses.
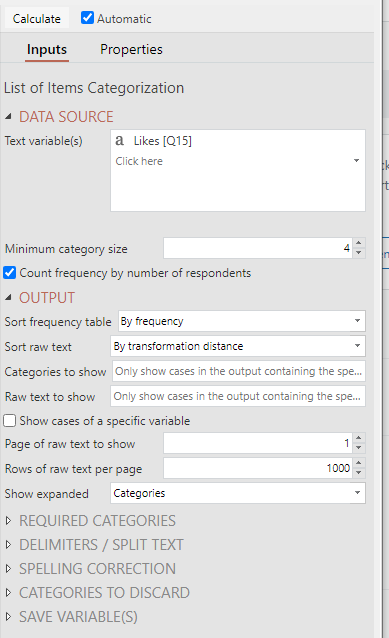
The output will calculate automatically:
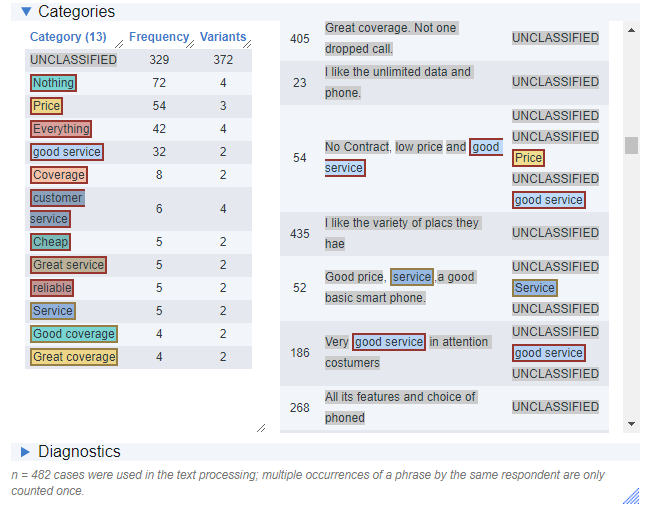
Interpreting the Output
The left side of the output lists the automatically generated categories. The number of individual responses that are put into each category is displayed in the frequency column. The variants indicate how many different specific variations of responses there are in each category. The right side of the output shows the raw (original) text and the normalized or categorized text. The normalized text is the “cleaned” text. In other words, this is the text after spell checking, stemming, word removals and other cleaning functions are performed.
The colored boxes around the word categories are randomly assigned to each category. The only purpose of this is to give specific words a unique style and make them easier to identify. There is no further meaning to this. If “Scientologist” is in a blue box, then all occurrences of “Scientologist” will be in a blue box. This makes it easier to recognize common categories.
How to Save the Categories to your Data Set
You can save the created categories to your data set as a new variable which can then be used in other analyses. Make sure that the output above is selected and then go to
- Create > Text Analysis > Advanced > Save Variable(s) > Categories.
A new multi-select variable is created and can be seen in the Variables and Questions tab. You can now use it like any of the other variables in your data to create tables, crosstabs, charts, and visualizations.
How to Use Automatic List Categorization to Transform Comma-Separated Pick Any to Categorical
Let's say you included a question in you wrote as a "pick any" question which asked "Which of the following countries did you visit last year? Please check all that apply", but instead of coming in as individual binary variables for each, the data comes in as comma separated data.
Is there a way to make this into a Pick Any format so I can get a list of countries respondents visited and the % of people that visited each country?
To do this, do the following:
1. Go to Create > Text Analysis > Automatic Categorization > List of Items
2. Q will add a new output to your project, select the text version of Countries visited in the Text variable(s) box.
3. Q will automatically run the categorization. Since this is really a Pick Any question at heart, the list is fixed, which makes this very simple. Once it is done running, scroll down in the Object Inspector on the right side of the page to the SAVE VARIABLE(S) section and click the Categories button.
Q will create new categories in your project, one that corresponds to each "mention" in the coded question (rather than answer choice). Select this new question on your Variables and Questions tab. It will look like this:
From here you can use this Pick Any - Compact question as you would a Pick Any. The table output will look like this:
See Also
How to Automatically Code Simple Text Variables
How to Do Automatic List Categorization of Text Data with Q
How to Automatically Categorize Unstructured Text Data
How to Automatically Extract Entities and Sentiment from Text
How to Calculate Sentiment Scores for Open-Ended Responses in Q