Introduction
This article describes how to go from a data set...
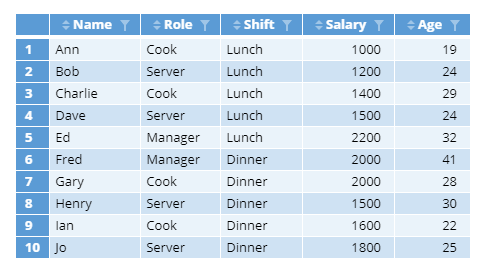
... to an R Output that aggregates specific fields according to the column average:
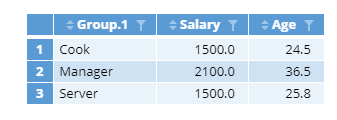
Requirements
- A raw data file or a Q project with a data file already imported
Method - Using aggregate()
In this example, we'll import a data set directly in R into our calculation, but you can also use raw variables in your code as well using cbind().
1. In the Report tree, right click and select Add R Output.
2. Enter the below code in the R CODE field:
# Import Excel data set
library(flipAPI)
data = DownloadXLSX("https://wiki.q-researchsoftware.com/images/1/1b/Aggregation_data.xlsx", want.row.names = FALSE, want.data.frame = TRUE)
# Aggregate data
agg = aggregate(data,
by = list(data$Role),
FUN = mean)
The first lines of code import the data set. This will differ depending on your data source. If importing an SPSS file, see How to Use R to Add Data Sets.
The rest of the code uses R's aggregation function.
- The first argument to the function is usually a data.frame.
- The by argument is a list of variables to group by. This must be a list even if there is only one variable.
- The FUN argument is the function which is applied to all columns (i.e., variables) in the grouped data. Because we cannot calculate the average of categorical variables such as Name and Shift, they result in empty columns, which I have removed for clarity.
- Any function that can be applied to a numeric variable can be used within aggregate. Maximum, minimum, count, standard deviation and sum are all popular.
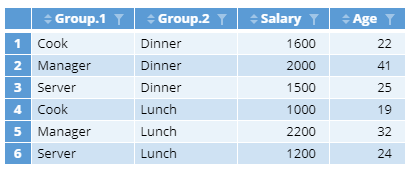
3. OPTIONAL: You can write your own function to pass into the aggregate FUN argument. Below is an example where the second largest value of each group is returned, or the largest if the group has only one record. Note also that the groups are formed by Role and by Shift together.
second = function(x) {
if (length(x) == 1)
return(x)
return(sort(x, decreasing = TRUE)[2])}
agg = aggregate(data,
by = list(data$Role, data$Shift),
FUN = second)
Method - Using dplyr::summarize()
The following example uses data.frame() to combine variables in the data set for aggregation.
1. In the Report tree, right click and select Add R Output.
2. Enter the below code in the R CODE field:
### combine the data
thedata = data.frame(Gender, Age,q2a_1,q2b_1, check.names=F)
### Aggregate data
#load packages with functions needed
library(dplyr)
library(verbs)
#aggregate the data
newdata <- thedata %>% #create a newdata table of the aggregated data
group_by(Gender, Age) %>% #group the calculations by Gender + Age
summarize(`Avg Coke Out` = Mean(q2a_1),
`Avg Coke Home` = Mean(q2b_1))
3. Click Calculate.
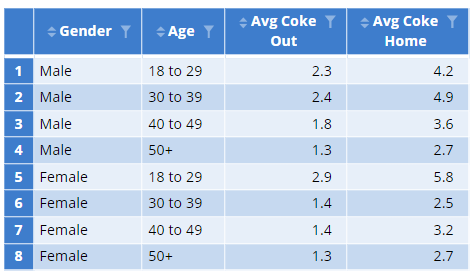
OPTIONAL: You can write your own function to use within the summarize function as well.
Next
How to Quickly Make Data Long or Wide Using R
How to Automatically Stack a Data Set
How to Perform Mathematical Calculations Using R
How to Standardize or Calculate Data within Subgroups in R