Introduction
This article describes how to extract data from an output:
Requirements
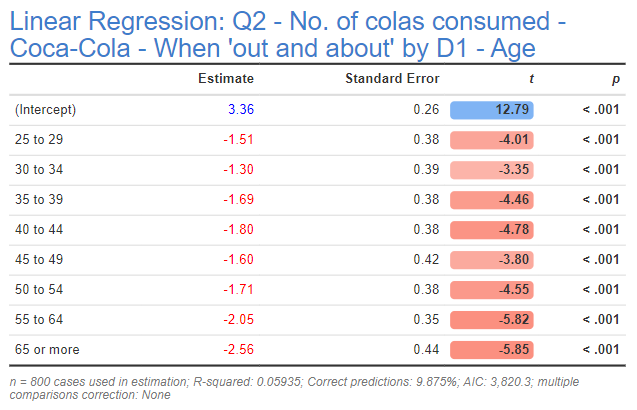
An output that you'd like to extract information about. In this example we are using a regression output with the Reference Name of glm. You find the Name under Properties > GENERAL in the object inspector.
Method - Reviewing Available Information in the Output
In order to extract data from an output, we need to know a bit more information about its structure. The simplest way to do this is to create a new R Output via right clicking in the Report tree and select Add R Output and explore the information available to R using one of the following functions. Note that many times there is underlying data and intermediate calculations that are stored in analyses that isn't present in what is shown in the output on the page.
Using names()
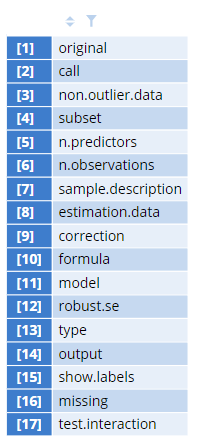
The names() function gives the most general overview of information in the object. It shows the highest-level names of the items available for extraction. Note that within each named item, there could be further nesting and the contents of each item can be any structure (i.e. single number, character vector, data.frame, etc).
Paste the following in the Properties > R CODE of your R Output:
names(glm)
The result contains a table that tells us what objects are contained within glm.
Using attributes()
The attributes() function gives the next layer of detail of the general information in the object as well as other meta data or stored data attached. It shows the highest-level names of the items available, the class() of the object, and any other specific attributes available for a particular output.
Paste the following in the Properties > R CODE of your R Output:
attributes(glm)
The result contains a list with details under each attribute (names, class, ChartData) of glm.

Using str()
The str() function gives the most detail available of ALL information in the object. If you haven't found what you need using names() or attributes(), then use str(). It is a text view of the list of everything available to extract in the object. You will see ".." in the list that denotes nesting so you can see what specific information is in each name/attribute. You can also see what type of data is contained and a preview of the data. Due to the large text output that this creates, it's easiest to review this info outside Q by using Edit > Copy to paste the info in Excel so you can search and more easily see the nesting.
Paste the following in the Properties > R CODE of your R Output:
str(glm)
The result contains a list with details of each available item to extract of glm. The .. denotes a nested element and multiple .. denotes deeper nesting to the $ item above. For example, to get coefficients, you would call glm$original$coefficients.

Method - Extracting Available Information
Using the Index
We can see that the 5th item is n.predictors. So, we can extract this item glm[5].

However, when we do this we get a bit of baggage with it. Rather than just getting the result, we are also getting the name as well. If we just want the result, we instead use glm[[5]]:
Objects contained within the output can have sub-objects (i.e., there is a hierarchy of objects). To access objects that reside in other objects, we can use names(glm[[19]]). The result will reveal the names of the items in the 17th item of glm, which is the summary. We can see that the 9th item is adj.r.squared. This means that to extract the adjusted R-squared statistic we could use glm[[9]][[19]] and get the below (after increasing the number of decimals):

Using $
The example above is a bit messy, however. If you type glm[[9]][[19]] instead of glm[[19]][[9]] you will get a different answer, but you may not spot it. Fortunately, we can instead reference parts of an object by name. For example: glm$summary$adj.r.squared
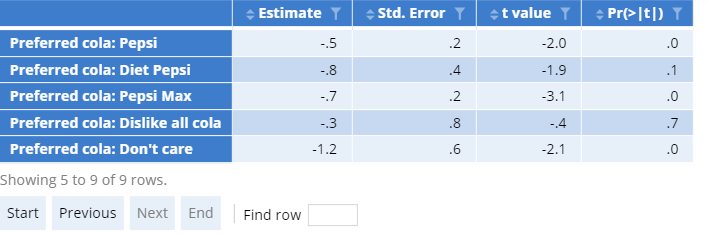
This example uses $ to extract the whole table of coefficients.
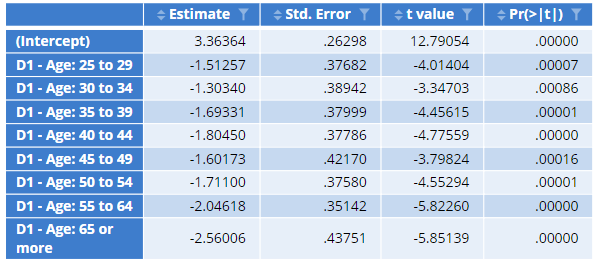
Note, as the table of coefficients is also the final visualized data, this can also be referenced using the attributes function:
attributes(glm)[["ChartData"]]
While in most cases the names function will be sufficient to extract the relevant information from your output, the attributes function can also extract the output class, and, if a visualization, the chart type, chart data and various other chart settings.
Using index and $ together
We can combine subscripting with using $. For example, we could extract all the standard errors from the regression model above by typing glm$summary$coefficients[, 2] or, equivalently, glm$summary$coefficients[, "Std.
Error"].
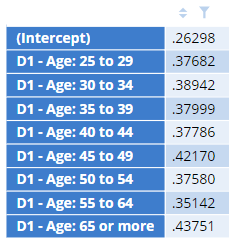
By having nothing before the comma in the bracket, it returns all the rows. By specifying just the column in the bracket, it returns just that column. And, do note that the actual text we have used here instead of Std. Error is actually a bit different to that used in the original output table at the top (Standard Error). The original table has been formatted for readability.
Using attr()
To pull off a specific attribute listed in the results of attributes(). You can subset the attributes() results as described above under Using $ or you can use the attr() function like so:
attr(model,"ChartData")
Method - MaxDiff Example: Extracting Model vs Respondent Means and Standard Deviations
Let's say your goal is extract the same means and standard deviation coefficients that appear in the MaxDiff output. While the following code will return similiar values, they won't exactly match the values in the output:
stats = as.data.frame(max.diff.2$parameter.statistics)
stats[,1,drop = FALSE]
This is because the code extracts the estimates of the mean and standard deviation coefficients of the model, instead of the mean and standard deviation of the respondent coefficients which is what appear in the output. While the two are similar they are distinct.
The following code should be used to extract the mean and standard deviation coefficients of the respondent coefficients:
colMeans(max.diff.2$respondent.parameters)
See Also
How to Customize the Standard R in R-based Outputs
How to Add a Custom R Output to your Report
How to Extract and Modify Attributes of a table using R
How to Extract Data from a Multiple Column Table with Nested Data