This article describes some of the ways to modify how Q conducts significance tests.
Column comparisons
The default significance testing approach in Q uses font color and arrows to highlight cells that stand out. You can change this to column comparisons by modifying the Show significance drop-down (top-middle of the screen) to Compare columns. You can also modify this for an entire project in Statistical Assumptions, and for future projects using Project Templates.
Statistical Assumptions
Many aspects of how tests are conducted can be modified in Statistical Assumptions, for a specific table, for the entire project, or for all future projects using Project Templates.
Changing the data
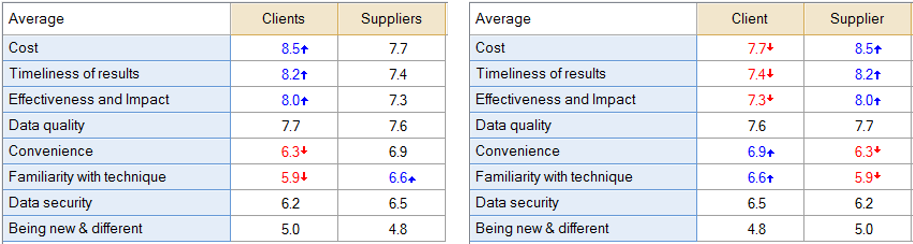
Q automatically determines how to conduct tests based on the properties of the data (see Tests Of Statistical Significance). Consequently, you can modify how Q performs tests by modifying the data. For example, consider the table below on the left.
By default, Q performs a somewhat exotic test on this table (see Summaries of Grid Questions (Number - Grid and Pick Any - Grid)). However, the tests that Q performs for such a table assume that the data is repeated measures (i.e., that the same people were providing data for all the cells in the table), whereas in this example people that have data in one column have no data in the other and vice versa. The most straightforward solution in this instance is to combine the two questions into one (e.g., using Merge Questions or Use as Template for Replication), and create the table using a crosstab, which is shown on the right. This right-most table is simply comparing the results within each row, which makes more sense for this data.
Rules and Table and Plot JavaScript
It is also possible to use Rules, either by writing them yourself or using pre-built Rules. See How to Modify Significance Tests Using Rules for more information.
Next
How to Show Statistical Significance in Q
How to Change Q's Default Statistical Assumptions When Setting Up Projects
How to Specify Columns to be Compared