Introduction
This article describes how to unstack a data set in Q using R. Unstacking can also be described as going from long to wide format like below:
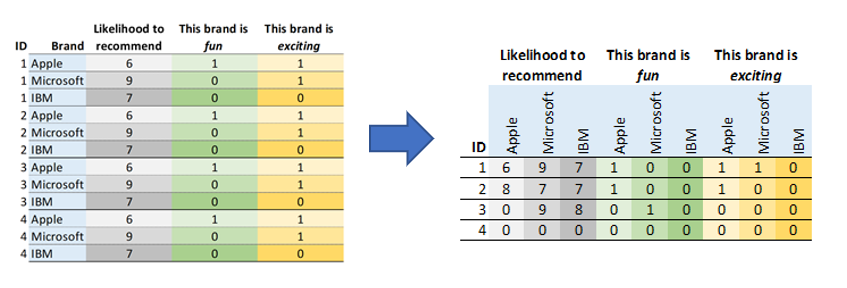
Method
1. Go to File > Data Sets > Add to Project > From R.
2. Enter a name for the data set under Name.
3. Paste the following code in the R CODE box and modify as needed:
#load the foreign package which reads .sav files into R
library(foreign)
#read in the file and convert it to a data frame in R for easy handling
#if loading a file from local drive, change all \ in the filepath to \\
tech = suppressWarnings(read.spss("https://wiki.q-researchsoftware.com/images/c/cf/Stacked_Technology.sav",
use.value.labels = TRUE,
to.data.frame = TRUE))
#load reshape2 package which has functions to stack/unstack data
library(reshape2)
#make the data wide
reshape(tech, #the data set to reshape
idvar = "original_case", #variable(s) used as the unique identifier for unstacking
timevar = "observation", #variable(s) to unstack by where each category becomes a column per variable in v.names
v.names = c("Q4A","Q4B","Q4C","Q4D","Q4E","Q4F","Q4G","Q4H","Q4I"), #variables to be unstacked into columns
direction = "wide") #whether to make the data long (stacked) or wide (unstacked)
Here, we use the foreign R package to import the stacked SPSS data set which looks like this:
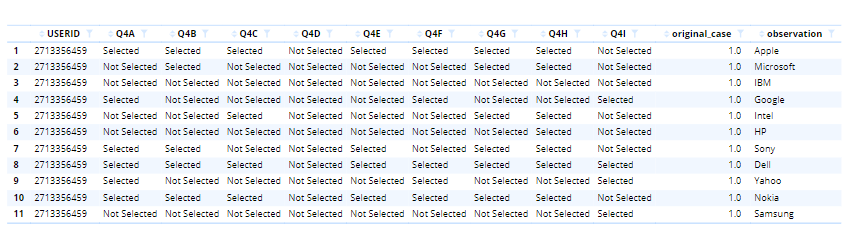
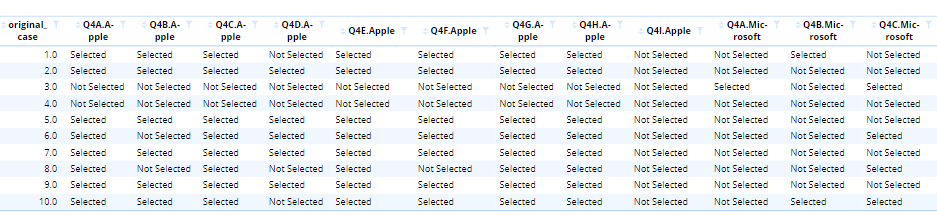
We next use the reshape function to create a non-stacked data frame.
- The idvar argument references the original record id which will be the same for each of the stacked observations for that record. This variable can be any unique identifier.
- The timevar argument references the variable which stores the item that the data set was originally stacked by, i.e. the brand in this example, or the variable you want to use for unstacking your selected variables in v.names. The categories within this variable are used for splitting the variables to be unstacked.
- The v.names argument identifies the variables to unstack.
- The direction argument tells the function that we want to unstack the data.
- In this case, this unstacking process will produce one row per original record number (original_case) whereby Q4A to Q4I will now be split by each of the brand categories in observation. Any other variables within the original data set will remain as is.
4. OPTIONAL: If you are unsure of the exact code that you need to use to unstack your data set you can prototype the code in an R Output by right clicking in the Report tree and selecting Add R Output and typing in your R CODE. This output will allow you to preview the results and modify your code as you go. You can then use that same code to add your R data set.
5. R doesn’t have the same level of metadata as some file types, like SSS and SAV. For example, variables in an R data frame do not have the concept of both Name and Label. Remember to add such information after you have added your data set.
See Also
How to Quickly Make Data Long or Wide Using R
How to Automatically Stack a Data Set
How to Perform Mathematical Calculations Using R
How to Standardize or Calculate Data within Subgroups in R